 ---
# Prometheus Metrics
> **Info:** Only available in the Growth tier and above on Hatchet Cloud
Hatchet exports Prometheus Metrics for your tenant which can be scraped with services like Grafana and DataDog.
## Tenant Metrics
> **Warning:** Only works with v1 tenants
Metrics for individual tenants are available in Prometheus Text Format via a REST API endpoint.
### Endpoint
```
GET /api/v1/tenants/{tenantId}/prometheus-metrics
```
### Authentication
The endpoint requires Bearer token authentication using a valid API token:
```
Authorization: Bearer
```
### Response Format
The response is returned in standard Prometheus Text Format, including:
- HELP comments describing each metric
- TYPE declarations (counter, gauge, etc.)
- Metric samples with labels and values
### Example Usage
```bash
curl -H "Authorization: Bearer your-api-token-here" \
https://cloud.onhatchet.run/api/v1/tenants/707d0855-80ab-4e1f-a156-f1c4546cbf52/prometheus-metrics
```
---
# Cancellation in Hatchet Tasks
Hatchet provides a mechanism for canceling task executions gracefully, allowing you to signal to running tasks that they should stop running. Cancellation can be triggered on graceful termination of a worker or automatically through concurrency control strategies like [`CANCEL_IN_PROGRESS`](./concurrency.mdx#cancel_in_progress), which cancels currently running task instances to free up slots for new instances when the concurrency limit is reached.
When a task is canceled, Hatchet sends a cancellation signal to the task. The task can then check for the cancellation signal and take appropriate action, such as cleaning up resources, aborting network requests, or gracefully terminating their execution.
## Cancellation Mechanisms
#### Python
```python
@cancellation_workflow.task()
def check_flag(input: EmptyModel, ctx: Context) -> dict[str, str]:
for i in range(3):
time.sleep(1)
# Note: Checking the status of the exit flag is mostly useful for cancelling
# sync tasks without needing to forcibly kill the thread they're running on.
if ctx.exit_flag:
print("Task has been cancelled")
raise ValueError("Task has been cancelled")
return {"error": "Task should have been cancelled"}
```
```python
@cancellation_workflow.task()
async def self_cancel(input: EmptyModel, ctx: Context) -> dict[str, str]:
await asyncio.sleep(2)
## Cancel the task
await ctx.aio_cancel()
await asyncio.sleep(10)
return {"error": "Task should have been cancelled"}
```
#### Typescript
```typescript
export const cancellation = hatchet.task({
name: 'cancellation',
fn: async (_, ctx) => {
await sleep(10 * 1000);
if (ctx.cancelled) {
throw new Error('Task was cancelled');
}
return {
Completed: true,
};
},
});
```
```typescript
export const abortSignal = hatchet.task({
name: 'abort-signal',
fn: async (_, { abortController }) => {
try {
const response = await axios.get('https://api.example.com/data', {
signal: abortController.signal,
});
// Handle the response
} catch (error) {
if (axios.isCancel(error)) {
// Request was canceled
console.log('Request canceled');
} else {
// Handle other errors
}
}
},
});
```
#### Go
```go
// Add a long-running task that can be cancelled
_ = workflow.NewTask("long-running-task", func(ctx hatchet.Context, input CancellationInput) (CancellationOutput, error) {
log.Printf("Starting long-running task with message: %s", input.Message)
// Simulate long-running work with cancellation checking
for i := 0; i < 10; i++ {
select {
case <-ctx.Done():
log.Printf("Task cancelled after %d steps", i)
return CancellationOutput{
Status: "cancelled",
Completed: false,
}, nil
default:
log.Printf("Working... step %d/10", i+1)
time.Sleep(1 * time.Second)
}
}
log.Println("Task completed successfully")
return CancellationOutput{
Status: "completed",
Completed: true,
}, nil
}, hatchet.WithExecutionTimeout(30*time.Second))
```
#### Ruby
```ruby
CANCELLATION_WORKFLOW.task(:check_flag) do |input, ctx|
3.times do
sleep 1
# Note: Checking the status of the exit flag is mostly useful for cancelling
# sync tasks without needing to forcibly kill the thread they're running on.
if ctx.cancelled?
puts "Task has been cancelled"
raise "Task has been cancelled"
end
end
{ "error" => "Task should have been cancelled" }
end
```
```ruby
CANCELLATION_WORKFLOW.task(:self_cancel) do |input, ctx|
sleep 2
## Cancel the task
ctx.cancel
sleep 10
{ "error" => "Task should have been cancelled" }
end
```
## Cancellation Best Practices
When working with cancellation in Hatchet tasks, consider the following best practices:
1. **Graceful Termination**: When a task receives a cancellation signal, aim to terminate its execution gracefully. Clean up any resources, abort pending operations, and perform any necessary cleanup tasks before returning from the task function.
2. **Cancellation Checks**: Regularly check for cancellation signals within long-running tasks or loops. This allows the task to respond to cancellation in a timely manner and avoid unnecessary processing.
3. **Asynchronous Operations**: If a task performs asynchronous operations, such as network requests or file I/O, consider passing the cancellation signal to those operations. Many libraries and APIs support cancellation through the `AbortSignal` interface.
4. **Error Handling**: Handle cancellation errors appropriately. Distinguish between cancellation errors and other types of errors to provide meaningful error messages and take appropriate actions.
5. **Cancellation Propagation**: If a task invokes other functions or libraries, consider propagating the cancellation signal to those dependencies. This ensures that cancellation is handled consistently throughout the task.
## Additional Features
In addition to the methods of cancellation listed here, Hatchet also supports [bulk cancellation](./bulk-retries-and-cancellations.mdx), which allows you to cancel many tasks in bulk using either their IDs or a set of filters, which is often the easiest way to cancel many things at once.
## Conclusion
Cancellation is a powerful feature in Hatchet that allows you to gracefully stop task executions when needed. Remember to follow best practices when implementing cancellation in your tasks, such as graceful termination, regular cancellation checks, handling asynchronous operations, proper error handling, and cancellation propagation.
By incorporating cancellation into your Hatchet tasks and workflows, you can build more resilient and responsive systems that can adapt to changing circumstances and user needs.
---
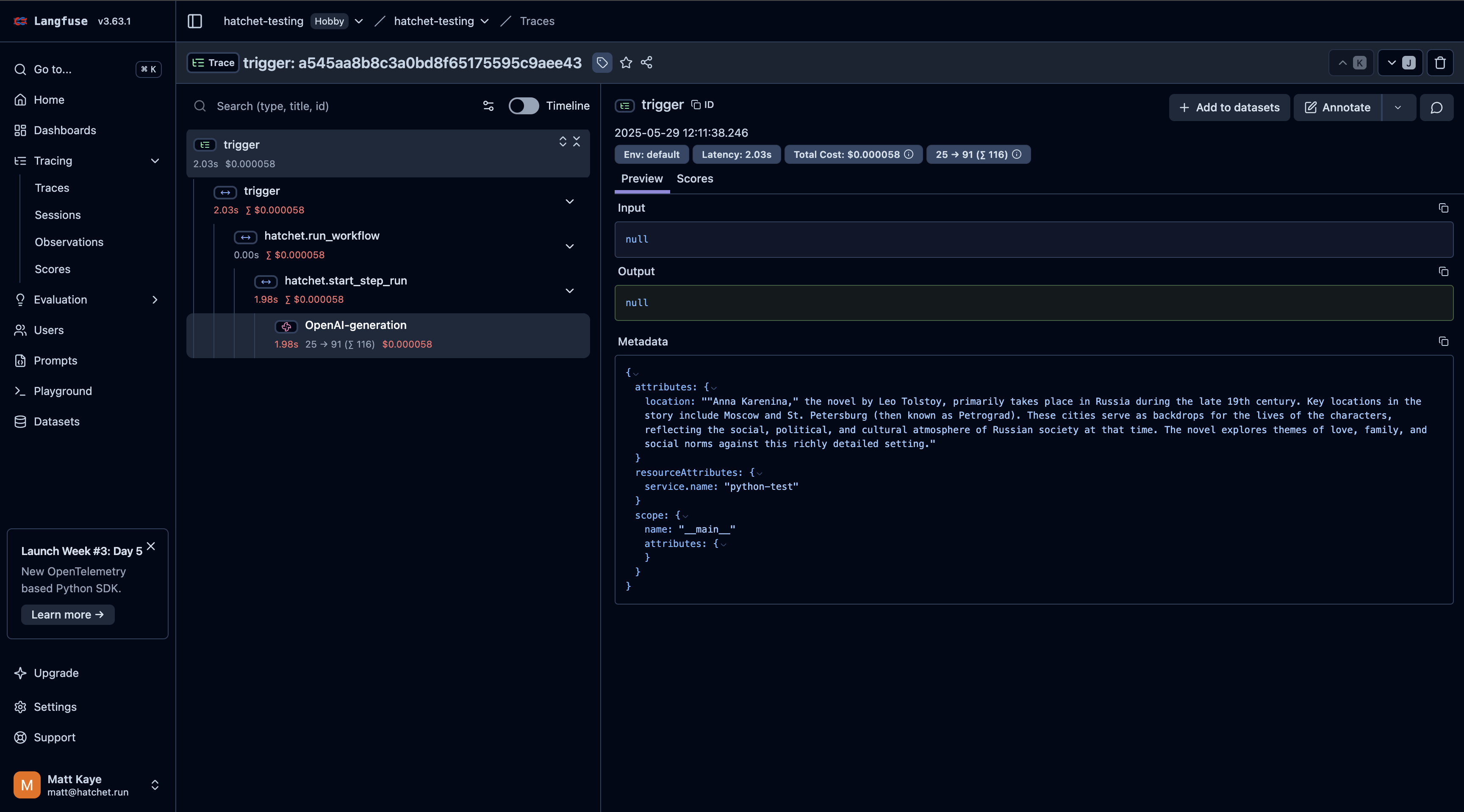
# Streaming in Hatchet
Hatchet tasks can stream data back to a consumer in real-time. This has a number of valuable uses, such as streaming the results of an LLM call back from a Hatchet worker to a frontend or sending progress updates as a task chugs along.
## Publishing Stream Events
You can stream data out of a task run by using the `put_stream` (or equivalent) method on the `Context`.
#### Python
```python
anna_karenina = """
Happy families are all alike; every unhappy family is unhappy in its own way.
Everything was in confusion in the Oblonskys' house. The wife had discovered that the husband was carrying on an intrigue with a French girl, who had been a governess in their family, and she had announced to her husband that she could not go on living in the same house with him.
"""
def create_chunks(content: str, n: int) -> Generator[str, None, None]:
for i in range(0, len(content), n):
yield content[i : i + n]
chunks = list(create_chunks(anna_karenina, 10))
@hatchet.task()
async def stream_task(input: EmptyModel, ctx: Context) -> None:
# 👀 Sleeping to avoid race conditions
await asyncio.sleep(2)
for chunk in chunks:
await ctx.aio_put_stream(chunk)
await asyncio.sleep(0.20)
```
#### Typescript
```typescript
const annaKarenina = `
Happy families are all alike; every unhappy family is unhappy in its own way.
Everything was in confusion in the Oblonskys' house. The wife had discovered that the husband was carrying on an intrigue with a French girl, who had been a governess in their family, and she had announced to her husband that she could not go on living in the same house with him.
`;
function* createChunks(content: string, n: number): Generator
---
# Prometheus Metrics
> **Info:** Only available in the Growth tier and above on Hatchet Cloud
Hatchet exports Prometheus Metrics for your tenant which can be scraped with services like Grafana and DataDog.
## Tenant Metrics
> **Warning:** Only works with v1 tenants
Metrics for individual tenants are available in Prometheus Text Format via a REST API endpoint.
### Endpoint
```
GET /api/v1/tenants/{tenantId}/prometheus-metrics
```
### Authentication
The endpoint requires Bearer token authentication using a valid API token:
```
Authorization: Bearer
```
### Response Format
The response is returned in standard Prometheus Text Format, including:
- HELP comments describing each metric
- TYPE declarations (counter, gauge, etc.)
- Metric samples with labels and values
### Example Usage
```bash
curl -H "Authorization: Bearer your-api-token-here" \
https://cloud.onhatchet.run/api/v1/tenants/707d0855-80ab-4e1f-a156-f1c4546cbf52/prometheus-metrics
```
---
# Cancellation in Hatchet Tasks
Hatchet provides a mechanism for canceling task executions gracefully, allowing you to signal to running tasks that they should stop running. Cancellation can be triggered on graceful termination of a worker or automatically through concurrency control strategies like [`CANCEL_IN_PROGRESS`](./concurrency.mdx#cancel_in_progress), which cancels currently running task instances to free up slots for new instances when the concurrency limit is reached.
When a task is canceled, Hatchet sends a cancellation signal to the task. The task can then check for the cancellation signal and take appropriate action, such as cleaning up resources, aborting network requests, or gracefully terminating their execution.
## Cancellation Mechanisms
#### Python
```python
@cancellation_workflow.task()
def check_flag(input: EmptyModel, ctx: Context) -> dict[str, str]:
for i in range(3):
time.sleep(1)
# Note: Checking the status of the exit flag is mostly useful for cancelling
# sync tasks without needing to forcibly kill the thread they're running on.
if ctx.exit_flag:
print("Task has been cancelled")
raise ValueError("Task has been cancelled")
return {"error": "Task should have been cancelled"}
```
```python
@cancellation_workflow.task()
async def self_cancel(input: EmptyModel, ctx: Context) -> dict[str, str]:
await asyncio.sleep(2)
## Cancel the task
await ctx.aio_cancel()
await asyncio.sleep(10)
return {"error": "Task should have been cancelled"}
```
#### Typescript
```typescript
export const cancellation = hatchet.task({
name: 'cancellation',
fn: async (_, ctx) => {
await sleep(10 * 1000);
if (ctx.cancelled) {
throw new Error('Task was cancelled');
}
return {
Completed: true,
};
},
});
```
```typescript
export const abortSignal = hatchet.task({
name: 'abort-signal',
fn: async (_, { abortController }) => {
try {
const response = await axios.get('https://api.example.com/data', {
signal: abortController.signal,
});
// Handle the response
} catch (error) {
if (axios.isCancel(error)) {
// Request was canceled
console.log('Request canceled');
} else {
// Handle other errors
}
}
},
});
```
#### Go
```go
// Add a long-running task that can be cancelled
_ = workflow.NewTask("long-running-task", func(ctx hatchet.Context, input CancellationInput) (CancellationOutput, error) {
log.Printf("Starting long-running task with message: %s", input.Message)
// Simulate long-running work with cancellation checking
for i := 0; i < 10; i++ {
select {
case <-ctx.Done():
log.Printf("Task cancelled after %d steps", i)
return CancellationOutput{
Status: "cancelled",
Completed: false,
}, nil
default:
log.Printf("Working... step %d/10", i+1)
time.Sleep(1 * time.Second)
}
}
log.Println("Task completed successfully")
return CancellationOutput{
Status: "completed",
Completed: true,
}, nil
}, hatchet.WithExecutionTimeout(30*time.Second))
```
#### Ruby
```ruby
CANCELLATION_WORKFLOW.task(:check_flag) do |input, ctx|
3.times do
sleep 1
# Note: Checking the status of the exit flag is mostly useful for cancelling
# sync tasks without needing to forcibly kill the thread they're running on.
if ctx.cancelled?
puts "Task has been cancelled"
raise "Task has been cancelled"
end
end
{ "error" => "Task should have been cancelled" }
end
```
```ruby
CANCELLATION_WORKFLOW.task(:self_cancel) do |input, ctx|
sleep 2
## Cancel the task
ctx.cancel
sleep 10
{ "error" => "Task should have been cancelled" }
end
```
## Cancellation Best Practices
When working with cancellation in Hatchet tasks, consider the following best practices:
1. **Graceful Termination**: When a task receives a cancellation signal, aim to terminate its execution gracefully. Clean up any resources, abort pending operations, and perform any necessary cleanup tasks before returning from the task function.
2. **Cancellation Checks**: Regularly check for cancellation signals within long-running tasks or loops. This allows the task to respond to cancellation in a timely manner and avoid unnecessary processing.
3. **Asynchronous Operations**: If a task performs asynchronous operations, such as network requests or file I/O, consider passing the cancellation signal to those operations. Many libraries and APIs support cancellation through the `AbortSignal` interface.
4. **Error Handling**: Handle cancellation errors appropriately. Distinguish between cancellation errors and other types of errors to provide meaningful error messages and take appropriate actions.
5. **Cancellation Propagation**: If a task invokes other functions or libraries, consider propagating the cancellation signal to those dependencies. This ensures that cancellation is handled consistently throughout the task.
## Additional Features
In addition to the methods of cancellation listed here, Hatchet also supports [bulk cancellation](./bulk-retries-and-cancellations.mdx), which allows you to cancel many tasks in bulk using either their IDs or a set of filters, which is often the easiest way to cancel many things at once.
## Conclusion
Cancellation is a powerful feature in Hatchet that allows you to gracefully stop task executions when needed. Remember to follow best practices when implementing cancellation in your tasks, such as graceful termination, regular cancellation checks, handling asynchronous operations, proper error handling, and cancellation propagation.
By incorporating cancellation into your Hatchet tasks and workflows, you can build more resilient and responsive systems that can adapt to changing circumstances and user needs.
---
# Streaming in Hatchet
Hatchet tasks can stream data back to a consumer in real-time. This has a number of valuable uses, such as streaming the results of an LLM call back from a Hatchet worker to a frontend or sending progress updates as a task chugs along.
## Publishing Stream Events
You can stream data out of a task run by using the `put_stream` (or equivalent) method on the `Context`.
#### Python
```python
anna_karenina = """
Happy families are all alike; every unhappy family is unhappy in its own way.
Everything was in confusion in the Oblonskys' house. The wife had discovered that the husband was carrying on an intrigue with a French girl, who had been a governess in their family, and she had announced to her husband that she could not go on living in the same house with him.
"""
def create_chunks(content: str, n: int) -> Generator[str, None, None]:
for i in range(0, len(content), n):
yield content[i : i + n]
chunks = list(create_chunks(anna_karenina, 10))
@hatchet.task()
async def stream_task(input: EmptyModel, ctx: Context) -> None:
# 👀 Sleeping to avoid race conditions
await asyncio.sleep(2)
for chunk in chunks:
await ctx.aio_put_stream(chunk)
await asyncio.sleep(0.20)
```
#### Typescript
```typescript
const annaKarenina = `
Happy families are all alike; every unhappy family is unhappy in its own way.
Everything was in confusion in the Oblonskys' house. The wife had discovered that the husband was carrying on an intrigue with a French girl, who had been a governess in their family, and she had announced to her husband that she could not go on living in the same house with him.
`;
function* createChunks(content: string, n: number): Generator